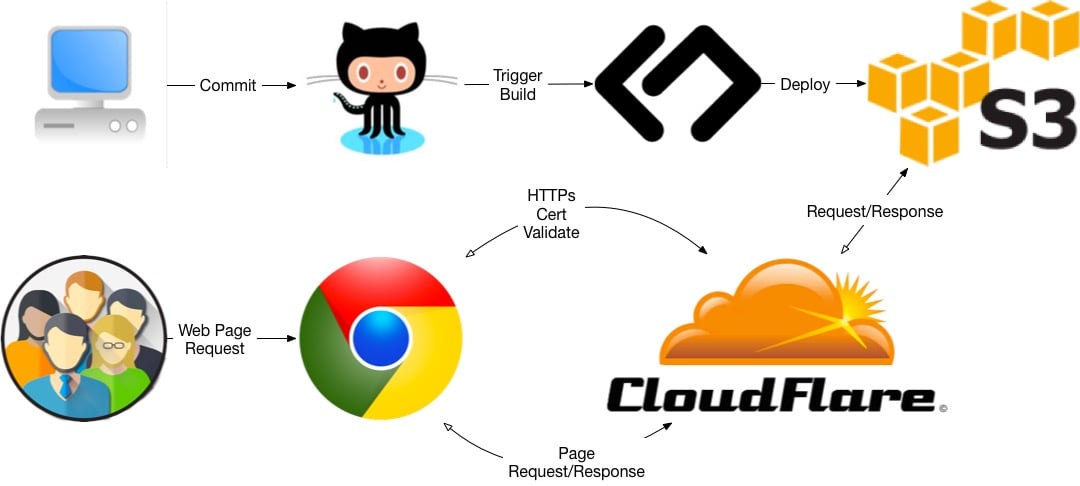
I have talked about teams needing to have a world class developer experience as a pre-requisite for a well functioning team. When teams lack such a setup, the most common response is a lack of time or buy in from stakeholders to build these things. With AI coding assistants being readily available to most developers today, the engineering effort and the cost investment for the business lesser reducing the barrier to entry.
Current State
This post showcases an actual codebase that has not been actively maintained for over 5 years but runs a product that is actively used. It is business critical but did not have the necessary safety nets in place. Let us go through the journey, prompts inclusive, on how to make the code quality of this repository better, one prompt at a time.
The project is a Django backend application that exposes APIs. We start off with a quick overview of the code and notice that there are tests and some documentation but a lack of consistent way to run and test the application.
The Journey
I am assuming you are running these commands using Claude Code (with Claude Sonnet 4 in most cases). This is equally applicable across any coding assistant. Results will vary based on your choices of models, prompts and the codebase.
Setting up Basic Documentation and Some Automation
If you are using a tool like Claude Code, run /init in your repository and you will get a significant part of this documentation.
Can you analyse the code and write up documentation in README.md that
clearly summarises how to setup, run, test and lint the application.
Please make sure the file is concise and does not repeat itself.
Write it like technical documentation. Short and sweet.
Next step is to start setting up some automation (like just files) to help make the project easier to use. This will take a couple of attempts to get right but here is a prompt you can start off with
Please write up a just file. I would like the following commands
`just setup` - set up all the dependencies of the project
`just run` - start up the applications including any dependencies
`just test` - run all tests
If you require clarifications, please ask questions.
Think hard about what other requirements I need to fulfill.
Be critical and question everything.
Do not make code changes till you are clear on what needs to be done.
This will give you a base structure for you to modify quickly and get up and running. If you README.md has a preferred way to run the application (locally vs docker), the just will automatically use it. If not, you will have to provide clarification.
Setting up pre-commit for Early Feedback
Let’s start small and build on it.
Please setup pre-commit with a single task to run all tests on every push.
Update the just script to ensure pre-commit hooks are installed locally
during the setup process.
We probably didn’t need to be this explicit but I find managing context and keeping tasks small mean I move a lot quicker.
Curating Code Quality Tools
Lets begin by finding good tools to use, create a plan for the change and then execute the plan. Start off by moving Claude Code to Plan mode (shift+tab twice)
What's a good tool to check the complexity of the python code this
repository has and lint on it to provide the team feedback as a
pre-commit hook?
It came back with a set of tools I liked but it assumed that the commit will immediately go green. In an existing large codebase with tech debt, this will not happen. Let’s break this down further.
The list of tools you're suggesting sound good.
The codebase currently will have a very large number of violations.
I want the ability to incrementally improve things with every commit.
How do we achieve this?
Creating a Plan
After you iterate on the previous prompt with the agent, you will get a plan that you’ll be happy with. The AI assistant will ask for permission to move forward and execute the plan but before doing so, it will be worth creating a save state. Imagine this as a video game save, if something goes wrong, come back and restore from this point. This also allows you to clear context since everything is dumped to markdown files on disk.
Can you create a plan that is executable in steps?
Write that plan to `docs/code-quality-improvements`.
Try to use multiple background agents if it helps speed up this process.
Give it a few minutes to analyse the code. In my case, the following files were created. README.md says that “Tasks within the same phase can be executed in parallel by multiple Claude Code assistants, as long as prerequisites are met”. You are ready to hit /clear and clear out the context window.
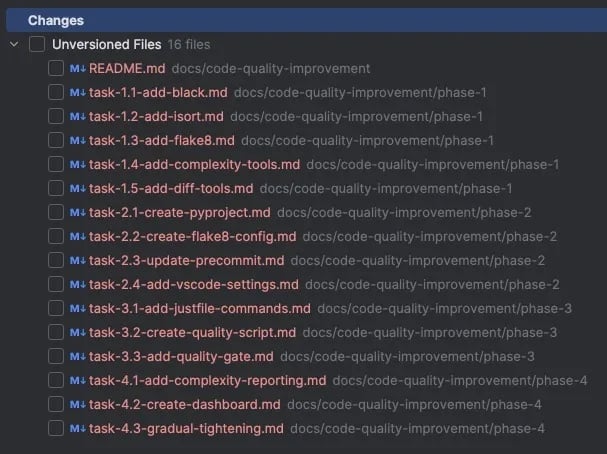
Phase 1 sets up the basic tools, phase 2 configures them, phase 3 focuses on integration and automation and phase 4 adds monitoring and focuses on improving the code quality.
Before executing the plan, I commit the plan (docs/code-quality-improvement). This allows me to track any changes that have been made. When executing the plan, I do not check in the changes made to the plan. This allows me to drop the plan at the end of the process. As a team, we have discussed potentially keeping the plan around as an artifact. To do so, you would have to ask Claude Code to use relative paths (it uses absolute paths when asking for files to be updated in the plan).
Executing the Plan
I would like to improve code quality and I have come up with a plan to do
so under `docs/code-quality-improvement`.
Can you analyse the plan and start executing it? The `README.md` has a
quick start section which tasks about how to execute different phases of the
plan. As you execute the plan, mark tasks as done to track state.
You will notice that Claude Code will add dependencies to requirements-dev.txt and try to run things without installing them. Also, it will add dependencies that do not exist. Stop the execution (by pressing Esc ) and use the following prompt to course correct
For every pip dependency you add to `requirements-dev.txt`, please run
`pip install`.
Before adding a dependency to the dependency file, please check if it is
available on `pip`.
Once phase 1 and phase 2 of the plan are complete, the following files are created and ready to be committed.
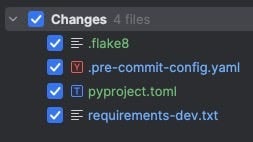
When the quality gates are added on phase 3, run the command once to test if everything works and create another commit. After this, I had to prompt it once more to integrate the lint steps into a simplified developer experience.
Please add `just lint` as a command to run all quality checks
Test the brand new lint command and then run a commit. Ask claude code to proceed to phase 4.

You might see Claude Code doubt a plan that it has created. It is a good question because the system is functional but if we prefer the more advanced checks, we should request it pushes on with Phase 4 implementation.
After phase 4, we have a codebase that checks for code quality every time a developer is pushing code. Our repository has pre-commit hooks for linting, runs all quality checks once before pushing. The quality checks will fail if the code added has unformatted files, imports in the wrong order, flake8 lint issues or functions with higher code complexity. It checks this only in the files being touched (because we told it that we had debt that needs to be reduced and all checks will not pass by default)
You still have debt, lets go over fixing this in the next step.
Fixing Existing Debt
Tools like isort can highlight issues and fix them. You should start off running such commands to fix the code. On most codebases, this will touch almost all of the files. The challenge with this is that all the issues that cannot be fixed automatically (like wildcard imports) will need to be fixed manually. This is where you make a choice either to fix issues manually or automatically. If you’re using Claude Code to fix these issues and there is a large number, you’re probably going to pay in upwards of $10 for this session on any decent sized codebase. I recommend moving to GitHub Copilot’s agent to help push down costs here.
Ask your coding assistant of choice to run the lint command and fix the issues. Most of them will stop after 1–2 attempts because the list is large. You can tell it to “keep doing this task till there are no linting errors left. DO NOT stop till the lint command passes”. If your context file (CLAUDE.md) does not talk about how to lint, be explicit and tell your coding assistant what the command to be run is.
What is Left?
If you look at the gradual-tightening task, it created a command to analyse the code and keep being gradually more strict. This command can either be run manually or automatically on a pipeline. One of the parameters it changes is the max-complexity which is set to 20 by default. This complexity will be reduced over a period of time. Similarly, the complexity check tasks have a lower bar to begin with and should be improved periodically to tighten the quality guidelines on this repository.
While our AI coding pair has helped design and improve the code quality to a large extent, the last mile has to be walked by all of our teammates. We now have a strong feedback mechanism for bad code that will fail the pipeline and stop code from being committed or pushed. The last bit requires team culture to be built. On one of my teams, we had a soft check in every retro to see if every member had made the codebase a little bit better in a sprint. A sprint is 10 days and “a little bit” can include refactoring a tiny 2–3 line function and making it better. The bar is really low but the social pressure of wanting to make things better motivated all of us to drive positive change.
Having a high quality codebase with a good developer experience is not a pipe dream and making it a reality is easier than ever with AI coding assistants like Claude Code or Copilot. What have you been able to improve recently? 😃
]]>